











Qwen2是什么?
Qwen2是阿里云通义千问团队开源的新一代大语言模型,推出了5个尺寸的预训练和指令微调模型,在中文英语的基础上,训练数据中增加了27种语言相关的高质量数据;代码和数学能力显著提升;增大了上下文长度支持,最高达到 128K tokens (Qwen2-72B-Iinstruct)。多个评测基准上的领先表现。现已在Hugging Face和ModelScope开源。
如何使用Qwen2?
目前,Qwen2已在Hugging Face和ModelScope上同步开源
相关资源地址如下:
- ModelScope模型地址:https://modelscope.cn/organization/qwen
- Qwen2项目博客:https://qwenlm.github.io/zh/blog/qwen2
- 在线体验地址:https://huggingface.co/spaces/Qwen/Qwen2-72B-Instruct
- GitHub地址:https://github.com/QwenLM/Qwen2
- Hugging Face模型地址:https://huggingface.co/Qwen
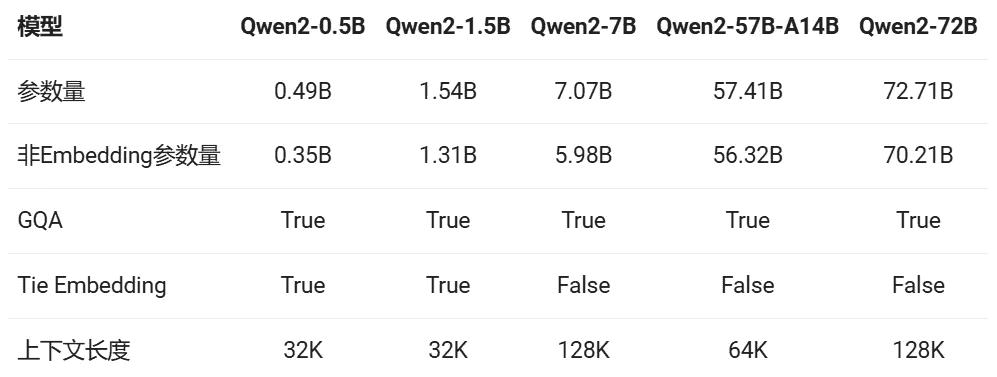
Qwen2系列包含5个尺寸的预训练和指令微调模型,其中包括Qwen2-0.5B、Qwen2-1.5B、Qwen2-7B、Qwen2-57B- A14B和Qwen2-72B。如下表所示:

AI 社区不应忽视中国机器学习生态系统
HuggingFace 平台和社区负责人 Omar Sanseviero 曾表示,全球 AI 社区在一定程度上忽视了中国机器学习生态系统的创新和成就。他指出,中国的研究人员和开发团队正在大语言模型、视觉模型、音频模型和扩散模型领域做出许多令人惊叹的工作,涌现出了如 Qwen、Yi、DeepSeek、Yuan、WizardLM、ChatGLM、CogVLM、Baichuan、InternLM、OpenBMB、Skywork、ChatTTS、Ernie、HunyuanDiT 等一系列杰出模型。
Qwen2 大模型开源,引发行业关注
近日,阿里云通义千问团队宣布了 Qwen2 大模型的开源消息,这一消息迅速在 AI 开发者社区引起了广泛关注。Qwen2-72B 大模型的性能超越了许多业内知名的开源模型,包括 Llama3-70B。此外,Qwen2-72B 也在性能上超过了中国国内的许多闭源大模型,如文心 4.0、豆包 pro、混元 pro 等。
Qwen2-72B 的优势
Qwen2-72B 是阿里云通义千问团队最新研发的大语言模型,其在多个关键指标上的表现均优于现有的顶尖模型。以下是 Qwen2-72B 的几大亮点:
1. **超高性能**:Qwen2-72B 在处理自然语言理解和生成任务时表现出色,其性能显著优于 Llama3-70B 以及其他许多国际领先的模型。
2. **广泛适用性**:Qwen2-72B 适用于多种应用场景,包括但不限于自然语言处理、机器翻译、对话系统等,能够为各类 AI 项目提供强大的技术支持。
3. **开源和社区支持**:Qwen2-72B 作为一个开源模型,所有人均可在魔搭社区和 Hugging Face 平台免费获取。这种开放策略不仅促进了技术的普及和应用,还鼓励了全球开发者的共同进步与合作。
中国 AI 模型的崛起
近年来,中国的 AI 研究和开发取得了显著的进步,许多团队在国际上崭露头角。以下是一些备受瞩目的中国 AI 模型:
– **Yi**:专注于视觉模型领域,表现优异。
– **DeepSeek**:在音频处理和扩散模型方面展现了卓越的技术实力。
– **Yuan** 和 **WizardLM**:在大语言模型方面具有极高的准确性和生成能力。
– **ChatGLM** 和 **CogVLM**:在对话系统和视觉语言模型方面取得了重大突破。
– **Baichuan**、**InternLM** 和 **OpenBMB**:在不同的 AI 应用场景中展现了广泛的应用潜力。
这些模型不仅在技术指标上表现优异,还在实际应用中展现了强大的功能和灵活性,为各行各业的智能化升级提供了有力支持。
Qwen2 大模型发布:引领AI新时代
今年2月,阿里云通义千问团队推出了Qwen1.5,迅速引起了广泛关注。如今,Qwen2的发布再次实现了性能的飞跃,进一步巩固了其在人工智能领域的领先地位。在上海人工智能实验室推出的权威模型测评榜单OpenCompass中,Qwen1.5-110B已领先于文心4.0等众多国内闭源模型。Qwen2的表现更加令人期待。
Qwen2 系列模型概述
Qwen2系列包括五种尺寸的基础和指令调优模型,分别为Qwen2-0.5B、Qwen2-1.5B、Qwen2-7B、Qwen2-57B-A14B和Qwen2-72B。这些模型均采用了GQA(Grouped-Query Attention)技术,不仅提升了推理速度,还显著降低了显存占用,使得用户能够更方便地体验到其优越性能。
多样化尺寸,满足不同需求
Qwen2系列在模型尺寸上进行了多样化设计,以满足不同用户的需求。无论是需要轻量化解决方案的小型模型,还是追求高性能的大型模型,Qwen2都能提供合适的选择。
小尺寸模型
针对小尺寸模型,由于embedding参数量较大,Qwen2系列采用了Tie Embedding方法,使输入和输出层共享参数,增加了非embedding参数的占比,从而在保持模型性能的同时,降低了计算资源的需求。
长上下文处理能力
所有Qwen2系列的预训练模型均在32K tokens的数据上进行训练,并在128K tokens时依然能在PPL(Perplexity)评测中取得优异表现。针对指令微调模型,Qwen2-7B-Instruct和Qwen2-72B-Instruct在长达128K tokens的上下文长度上表现出色,这对于长序列理解任务具有重要意义。
多语言支持与优化
研究团队在多语言预训练和指令微调数据的规模和质量上投入了大量精力,提升了模型的多语言能力。除了中英文之外,Qwen2还增强了对27种其他语言的支持,并针对多语言场景中常见的语言转换(code switch)问题进行了优化,显著降低了语言转换的发生概率。
性能与优化
Qwen2-72B在多个基准测试中表现优异,包括自然语言理解、知识、代码、数学及多语言等方面,均显著超越当前领先的开源模型,如Llama-3-70B和Qwen1.5-110B。这主要得益于其预训练数据及训练方法的优化。
预训练与微调
大规模预训练后,研究团队对模型进行了精细的微调,以提升其智能水平,使其表现更接近人类。微调过程遵循了规模化和减少人工标注的原则,采用多种自动方法获取高质量、可靠、有创造力的指令和偏好数据。
创新训练方法
团队结合了有监督微调、反馈模型训练以及在线DPO(Dual-Path Optimization)等方法,并采用在线模型合并的方法减少对齐税。这些创新方法不仅提升了模型的代码、数学、推理、指令遵循、多语言理解等能力,还使其在基准测试中表现出色。
代码与数学能力提升
在代码方面,Qwen2融入了CodeQwen1.5的成功经验,实现了在多种编程语言上的显著效果提升。在数学方面,大规模且高质量的数据帮助Qwen2-72B-Instruct实现了数学解题能力的飞升。
数据统计
数据评估
本站GG在线导航提供的魔搭社区(Qwen2)都来源于网络,不保证外部链接的准确性和完整性,同时,对于该外部链接的指向,不由GG在线导航实际控制,在10 7 月, 2024 5:10 上午收录时,该网页上的内容,都属于合规合法,后期网页的内容如出现违规,可以直接联系网站管理员进行删除,GG在线导航不承担任何责任。





